RAG Explained: How to Build AI Assistants That Don’t Hallucinate (Enterprise Search Playbook)
The fastest way to lose trust in an AI assistant is simple:
It answers confidently… and it’s wrong.
That’s the “hallucination problem”—and the fix isn’t just a better prompt. The real fix is RAG: Retrieval-Augmented Generation.
RAG is how you build AI systems that answer using your real documents (policies, tickets, specs, wikis) instead of guessing.
If you liked the systems approach in AI Second Brains at Work, this article is the technical foundation underneath “second brain search” at scale.
What Is RAG (Retrieval-Augmented Generation)?
RAG combines two capabilities:
- Retrieval: find the most relevant pieces of your knowledge base
- Generation: have an LLM write a helpful answer grounded in those sources
Instead of:
- “LLM, answer from memory”
You do:
- “LLM, answer using these documents”
This is why modern AI copilots in companies feel more trustworthy than generic chatbots.
Why Prompts Alone Don’t Solve Hallucinations
Prompts can improve style and structure, but they can’t reliably enforce truth.
If the model doesn’t have your context, it fills gaps with “best sounding” text.
For decision-heavy teams, that’s dangerous—especially when AI is used for strategy and execution. (Related: The Future of AI in Business: Beyond Automation and Strategic Problem-Solving Framework)
RAG gives you:
- grounded answers
- traceability (where did that come from?)
- updatable knowledge (change docs → change answers)
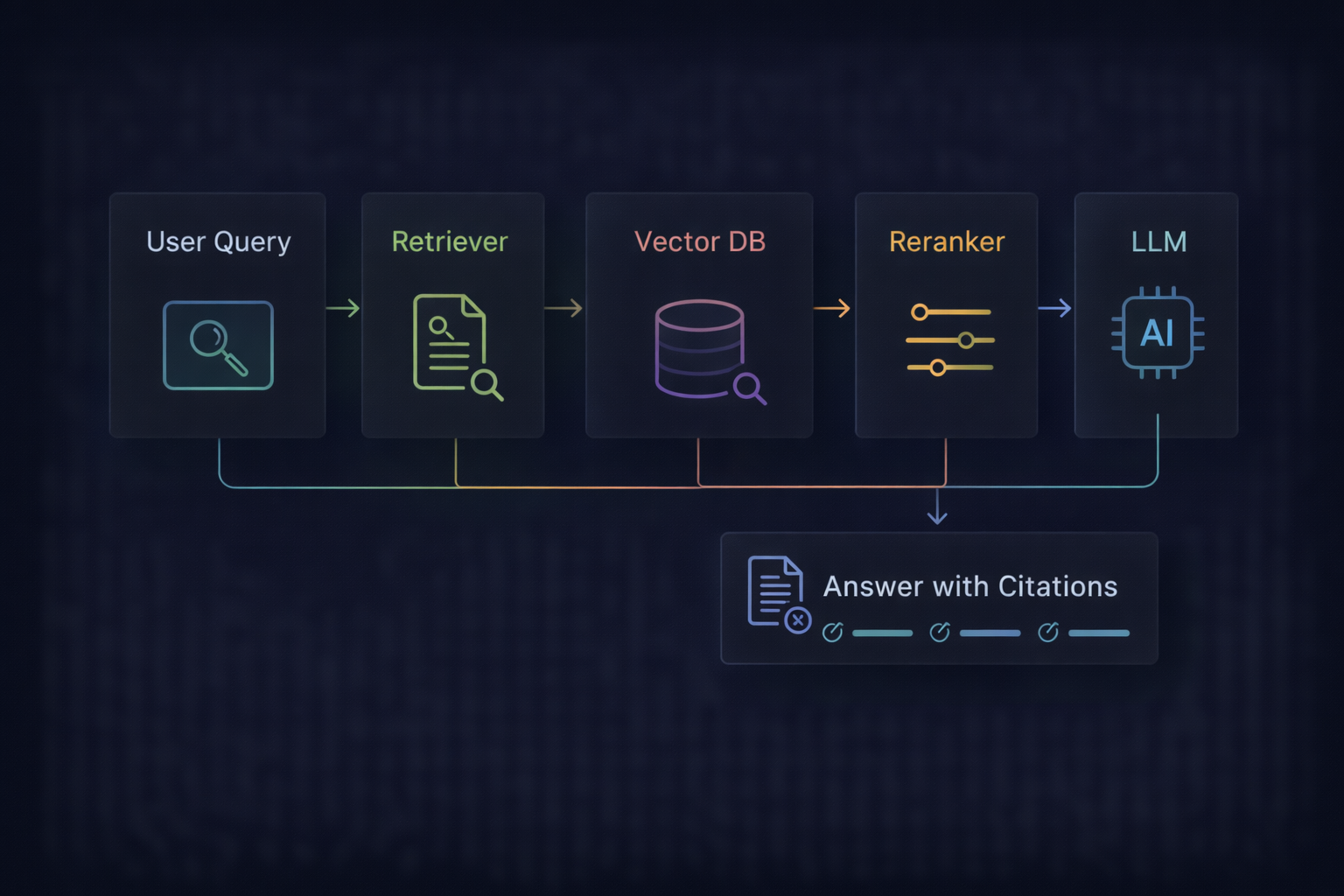
The Core RAG Architecture (Simple Version)
A practical RAG stack:
- Ingest documents (Notion, Drive, PDFs, tickets, GitHub)
- Chunk the text (split into small passages)
- Create embeddings (vectors) for each chunk
- On query: retrieve top-k relevant chunks
- Re-rank (optional, but recommended)
- Generate answer using retrieved chunks
- Return answer + citations/links

If your company is remote-first, RAG becomes the nervous system of your org—because it turns scattered async knowledge into instant answers. (Related: Remote-First Culture)
The 5 RAG Mistakes That Break Quality
1) Bad chunking
Too large → retrieval is noisy
Too small → missing context
Rule of thumb:
- chunks ~200–600 tokens
- overlap small but meaningful
- keep headings + metadata
2) No metadata
Without tags, you can’t filter by:
- project, owner, date, doc type, customer, region
Metadata is what makes RAG feel “smart,” not just “searchy.”
3) Skipping re-ranking
Basic vector retrieval is good. Re-ranking is what makes it great.
A re-ranker improves top results by judging relevance more precisely.
4) No freshness strategy
Old docs ruin answers.
You need:
- deprecation rules
- doc owners
- “latest wins” logic
This is exactly why “review loops” matter in an AI second brain: AI Second Brains at Work
5) No evaluation (you’re guessing)
If you don’t measure quality, you can’t improve it.

How to Evaluate a RAG Assistant (What to Measure)
Track these 6 metrics:
- Groundedness – does the answer reflect sources?
- Citation coverage – are citations present when claims are made?
- Answer correctness – judged by humans on a test set
- Retrieval precision – are the retrieved chunks actually relevant?
- Latency – does it answer fast enough for real use?
- Cost per answer – important at scale
Even a lightweight evaluation set (50–100 real questions) will outperform “vibes-based iteration.”
A Content Pipeline That Keeps Answers Accurate
RAG is only as good as your docs.
So treat docs like production systems:
- ownership (DRI)
- templates
- review cadence
- deprecation and archiving
This pairs perfectly with resilient product thinking: Building Resilient Digital Products

Real Use Cases That Drive ROI (Fast)
1) Internal engineering copilot
- “How do we deploy?”
- “Where is the auth middleware?”
- “What did we decide in the last architecture review?”
2) Sales + customer success assistant
- “Summarize account history and open risks”
- “Find relevant case studies and pricing rules”
- “Draft a renewal email grounded in call notes”
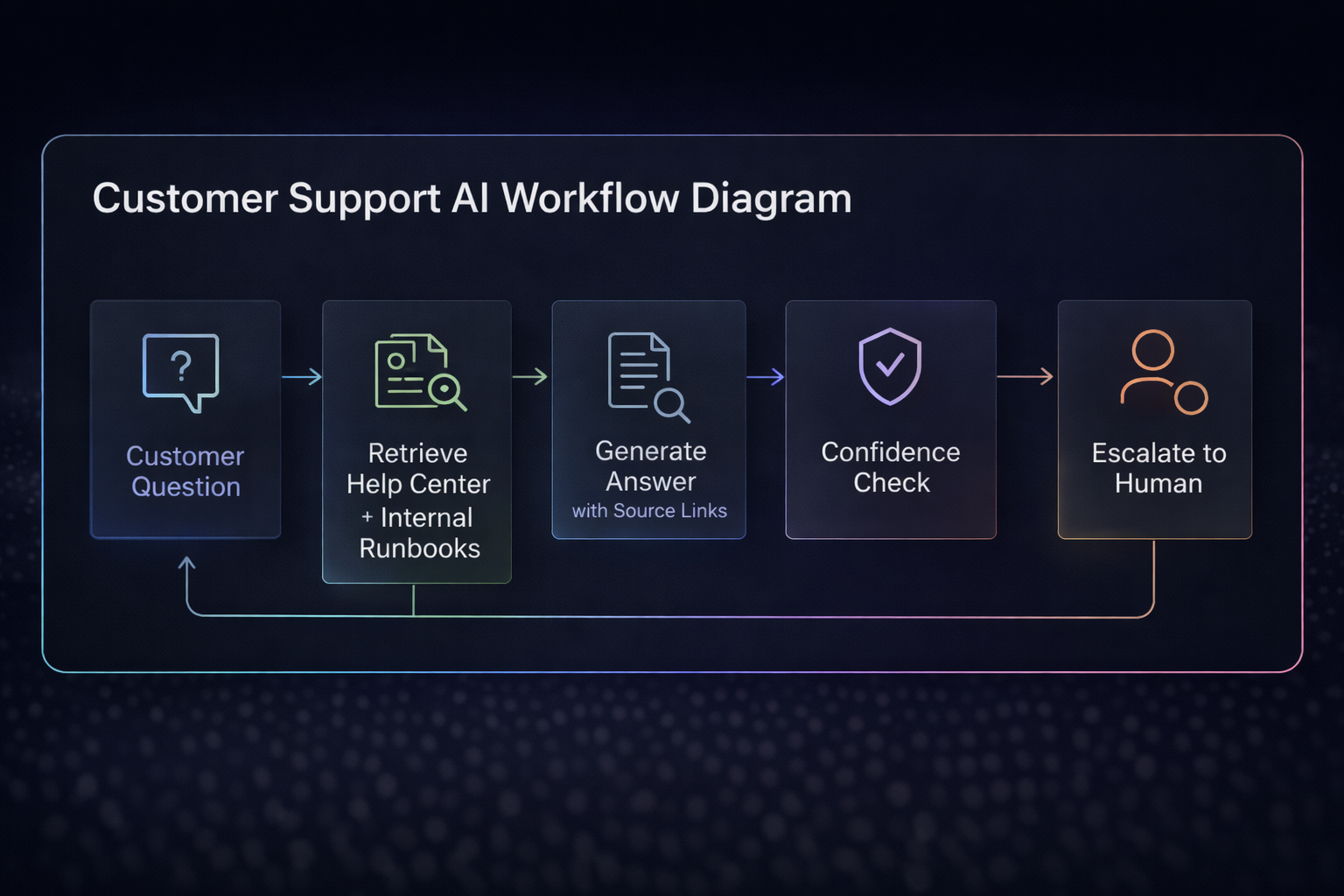
3) Customer support RAG bot
- answers from your real help center + internal runbooks
- escalates when confidence is low
- links sources every time
External References (Worth Bookmarking)
- NIST AI RMF (risk management mindset that fits AI assistants)
- OWASP Top 10 for LLM Apps (threats like prompt injection, data leakage)
- If you’re building governance alongside RAG, see: AI Governance for Small Teams
If You Want Help Building This for Your Company
At Zdravevski Professionals, we design and implement:
- RAG + enterprise search
- internal copilots and second brains
- security + governance
- workflows that teams actually adopt
👉 Get in touch with us and we’ll map your current knowledge chaos into a system your team can trust.